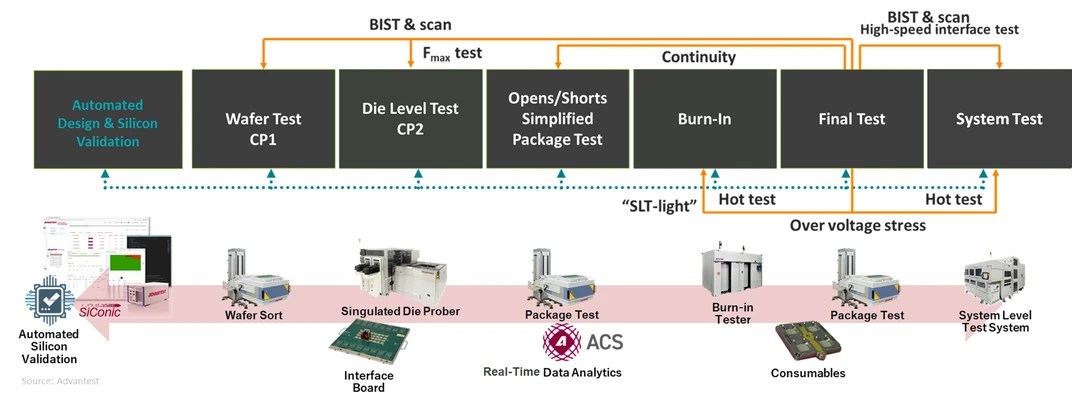
Test Distribution Evolves To Meet AI Challenges
The issue is no longer demand alone; it is whether the surrounding infrastructure is ready.
- Semiconductor Engineering reported a development that could affect hyperscalers & cloud planning.
- The practical issue is whether demand can be converted into reliable capacity on schedule.
- Watch execution details, customer commitments, and any bottlenecks around power, cooling, silicon, or permitting.
Semiconductor Engineering reported: ATE is evolving from a pure defect-detection system to one that provides system-level validation supported by AI software tools. The proliferation of artificial intelligence (AI) is driving rapid acceleration of the semiconductor market, which analysts now predict will reach $1 trillion this year. Many semiconductor devices will be the GPUs that populate the data centers that run AI workloads. Driven by strong, sustained investments from hyperscaler operators, high-performance computing (HPC)/AI data centers are expected to account for a large portion of the market. This market is driven by the growing demand for computational capability, with training computing requirements for generative AI models having increased fourfold each year since 2018 in terms of floating-point operations per second (FLOPS). In addition, semiconductors will also find increasing use in consumer-facing AI-related products such as AI-enabled PCs, smartphones, artificial-reality systems, autonomous taxis, and humanoid robots. As the market expands, the semiconductor devices themselves are evolving. Moore's Law is making less of a contribution to successive process generations as it reaches fundamental physical limits, so chip designers are turning to More than Moore—they are building larger 3D packages with more chiplets and accelerator cores, as well as voltage regulators and passive devices inte.
The important part is what the report says about cloud infrastructure as a working system, not just as a demand story. The constraint is not just chip supply. Advanced compute depends on packaging, memory, networking, power delivery, and the ability to land systems inside facilities that can actually run them at high utilization.
That is the reason the development deserves attention beyond the immediate headline. The underappreciated variable is deployment readiness across networking, power, and packaging, not just chip availability.
That matters for buyers because the useful capacity is the installed, cooled, powered cluster, not the purchase order. It also matters for suppliers because component shortages can shift bargaining power quickly across the stack.
The financial question is whether this improves pricing power, secures scarce capacity, or exposes execution risk that is still being discounted, the operating question is procurement timing, facility readiness, power access, and whether adjacent constraints slow deployment, and the customer question is whether this changes build sequencing, partner dependence, or the cost of scaling clusters across regions.
There is also a timing issue. In AI infrastructure, announcements often arrive before the hard parts are visible: interconnection queues, equipment lead times, operating approvals, financing conditions, and the practical work of matching customer demand to physical capacity.
For readers tracking this market, the useful lens is less about whether demand exists and more about where it can be served without delay. A small operational change can matter if it gives operators more flexibility, improves utilization, or exposes a bottleneck that had been hidden inside a broader growth story.
The next signal to watch is customer commitments, infrastructure readiness, and any signs that power, cooling, silicon supply, or permitting becomes the real bottleneck. The next test is whether delivery schedules, memory availability, and deployment readiness move together or start to diverge.